Using YouTube’s Python API for Data Science | Tutorial 2018 Towards DataScience com
Part 1: Using YouTube’s Python API for Data Science
https://towardsdatascience.com/tutorial-using-youtubes-annoying-data-api-in-python-part-1-9618beb0e7ea
A simple technique for searching YouTube’s vast catalog

Last week, I wrote a quick guide to using Google’s Speech Recognition API, which I described as “kinda-sorta-really confusing.” Well, guess what? Their YouTube Data API isn’t super clear either.
If you’re an expert coder with decades of experience, you can probably stop reading right now. However, if you’re an intermediate or self-taught programmer (like myself), this guide should help provide a jump-start to using YouTube for data science.
In the interest of time and overall readability, I’ve decided to break this tutorial into multiple parts. In part one, we will focus on getting the API library installed and authenticated, in addition to making simple keyword queries.
The parts to come will focus on other types of tasks, like comment collection, geographic queries and working with channels.
To complete this tutorial, you’ll need the following tools:
- Python 2.7
- A Google account
Getting started
1) Clone the GitHub repository
git clone https://github.com/spnichol/youtube_tutorial.git cd youtube_tutorial
2) Installing YouTube Official Python Client Library
3) Activating YouTube API
Note:In order to complete this step, you need to have a “project” created. If you’re unsure how to do this, check out my Speech Recognition tutorial for a quick guide.
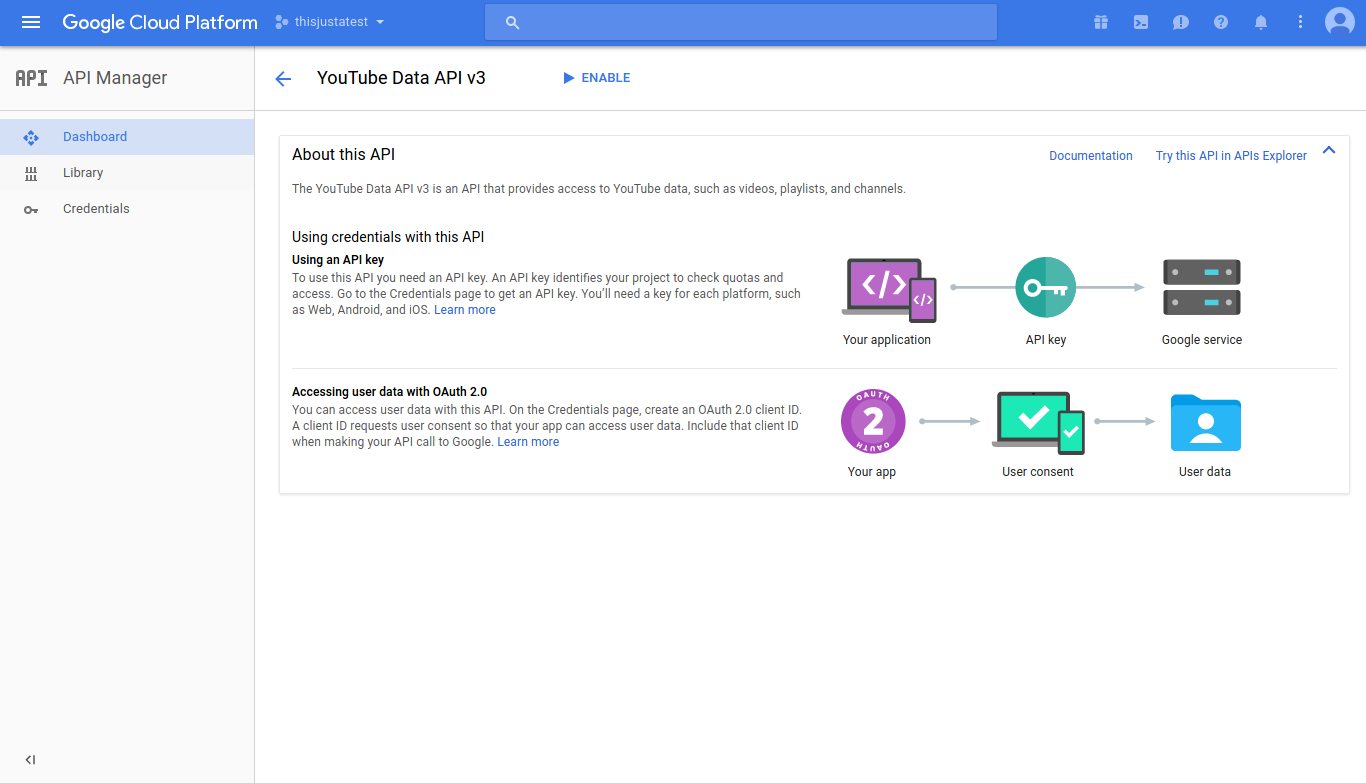
Head over to the Google Cloud Console, click the hamburger menu on the top left-hand corner and select “API Manager”.
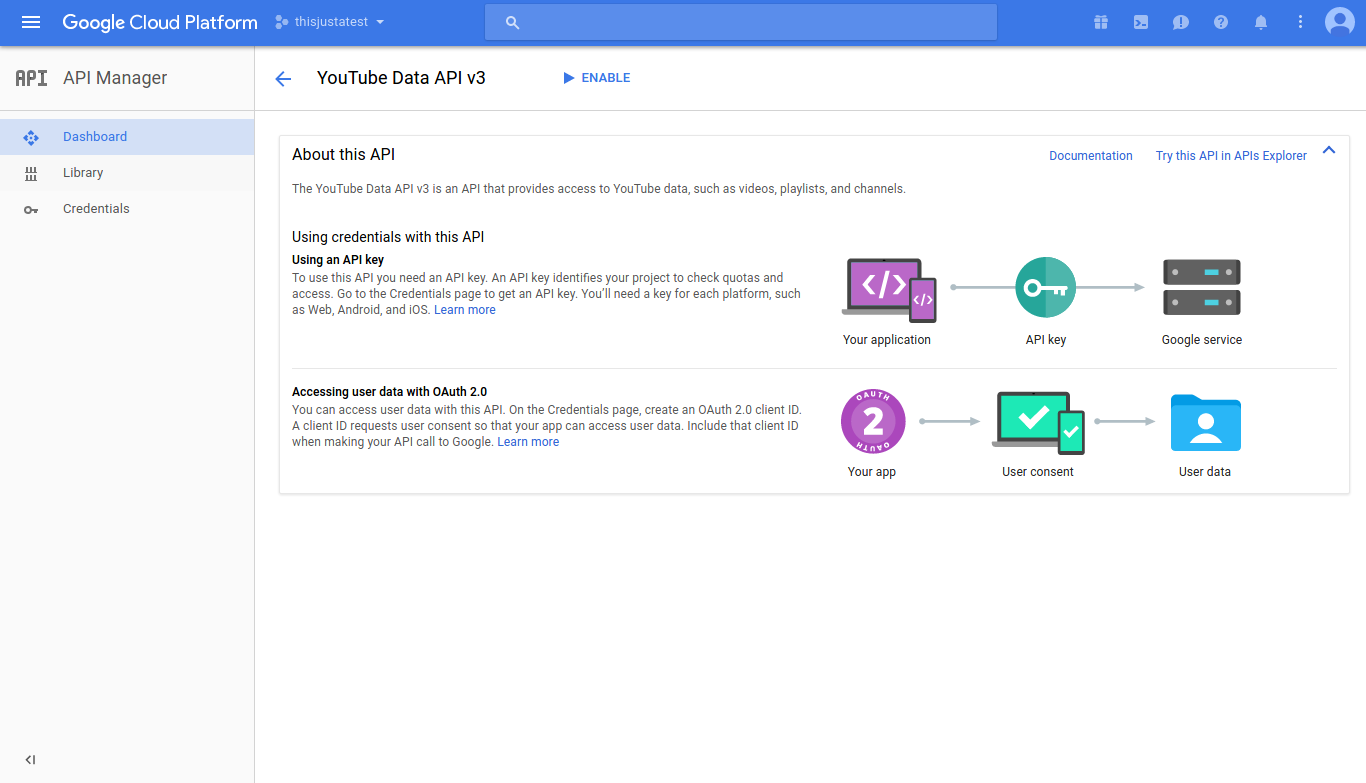
Select “YouTube Data API” from the YouTube APIs.

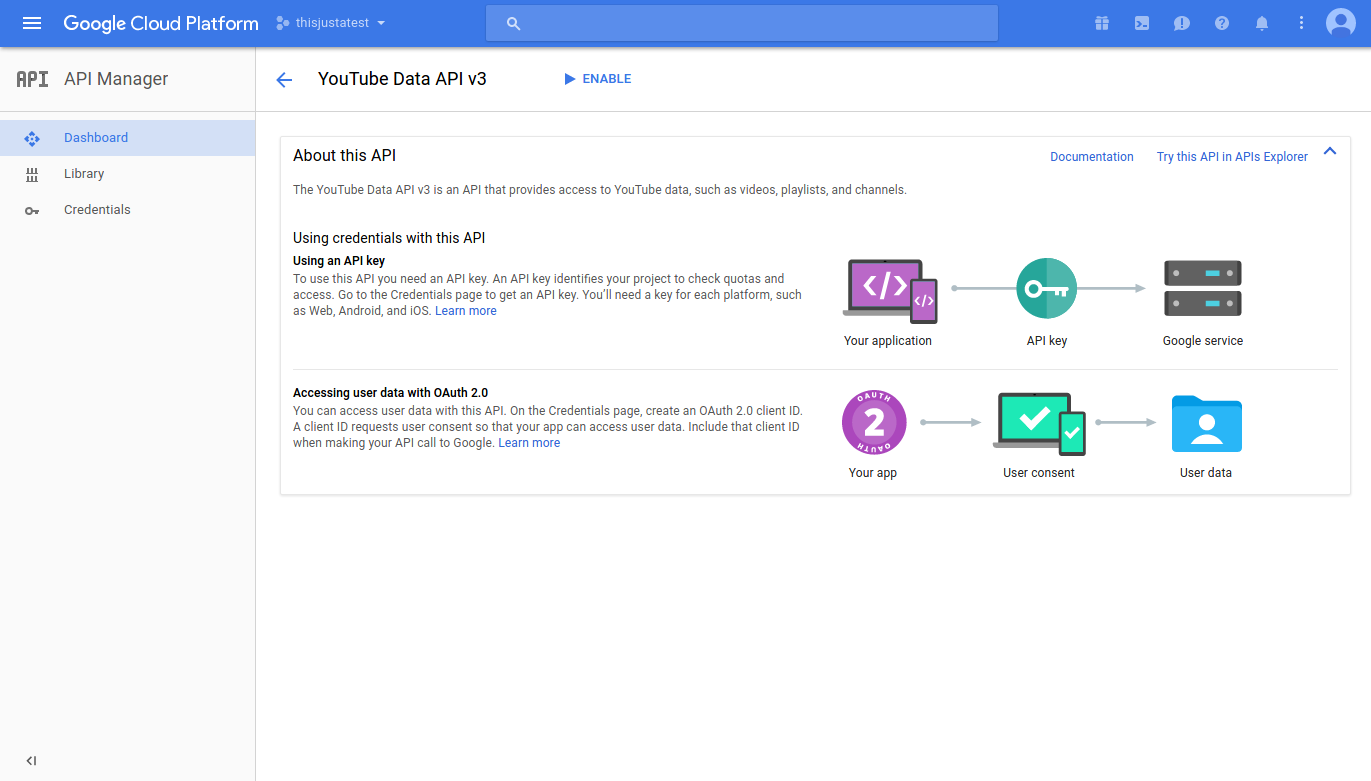
Click “Enable”
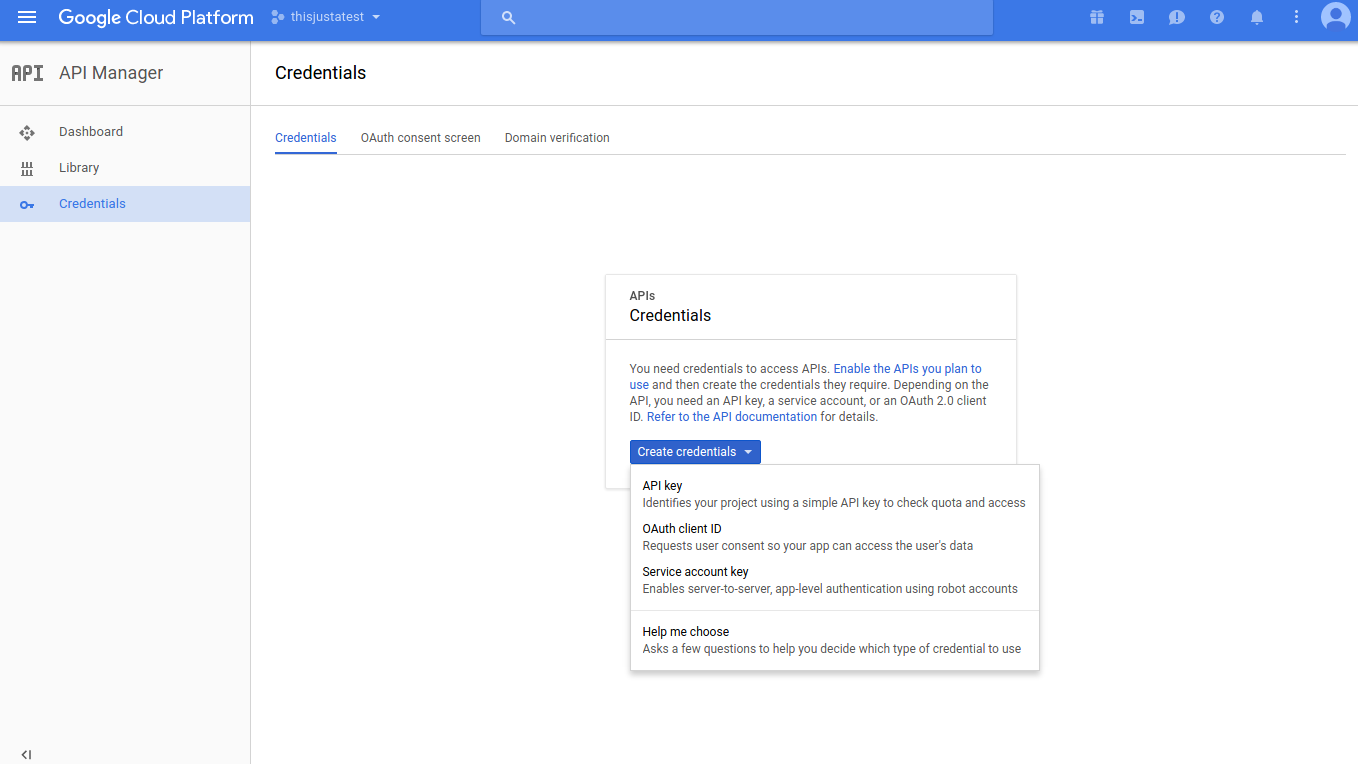
Click “Credentials” from the left-hand navigation panel and select “Create credentials.” You’ll want to choose API key from the drop-down list. You should see a message that says “API key created” with the alphanumeric API key. Copy and save this in a safe place!
Setting up our Python scripts
Open youtube_videos.py in your code editor. This is a heavily modified version of YouTube’s sample code.
Replace the DEVELOPER_KEY variable on the 5th line with the API key we created earlier and save the file.
Cool, cool, cool. We’re ready to start writing the code to do our keyword queries. Go ahead and create a new python script and save it in the same directory.
Setting up our Python scripts
We want to be able to use the functions in the youtube_search.py file where we saved our API key. One way to do this is by appending that directory to our Python path.
1) Append directory to Python path
2
sys.path.append("/home/your_name/youtube_tutorial/")
2) Import
1 | <strong class="markup--strong markup--p-strong">youtube_search</strong> |
function
Now that we have our path set, we can introduce the
1 | youtube_search |
function from the youtube_videos.py file with a simple import statement.
Let’s also import the json library, since it will come in handy when parsing the JSON output of the API.
Great. We’re ready to try a quick keyword search with our youtube_search function.
4) Test out
1 | <strong class="markup--strong markup--p-strong">youtube_search</strong> |
function.
Let’s assume we love fidget spinners (we don’t) and we want to see what videos YouTube has about them.
2
test
Your output should look like this:
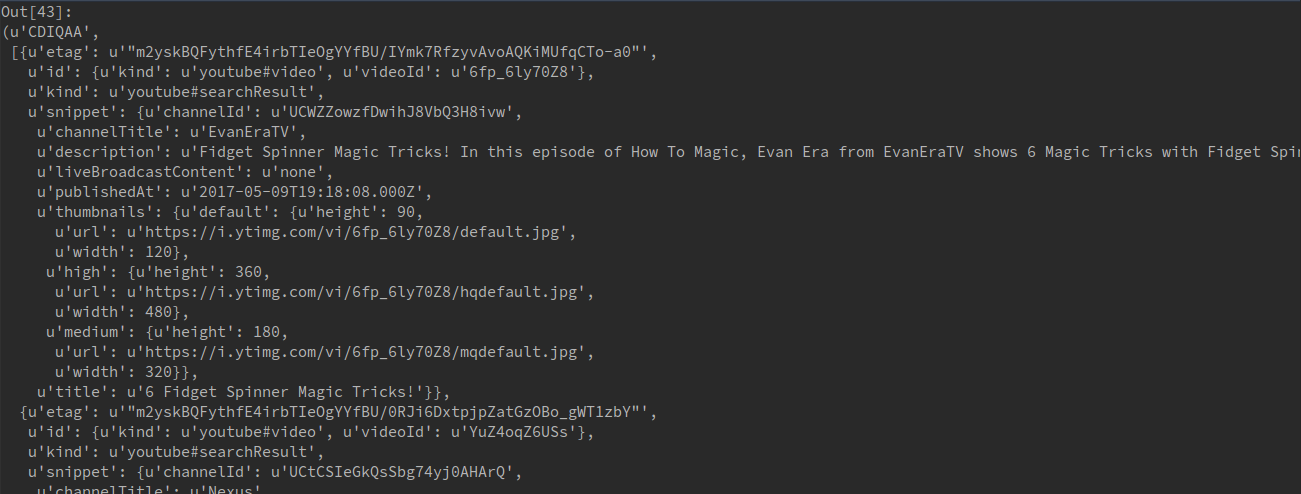
The output of our
1 | youtube_search |
is a tuple of len = 2. The first item is some weird six-character string. The second item is a bunch of JSON. Let’s ignore the weird six-character string for a bit and select only the JSON.
2
len(just_json)
Now you should have this:

Now we can see we have a JSON object of len = 50. Each item is a YouTube video with details about that video, such as the ID, title, date published, thumbnail URL, duration, etc.
Let’s say we want to get the title of a video, we can easily loop through and parse it with the JSON library.
2
print video['snippet']['title']
This gives us:
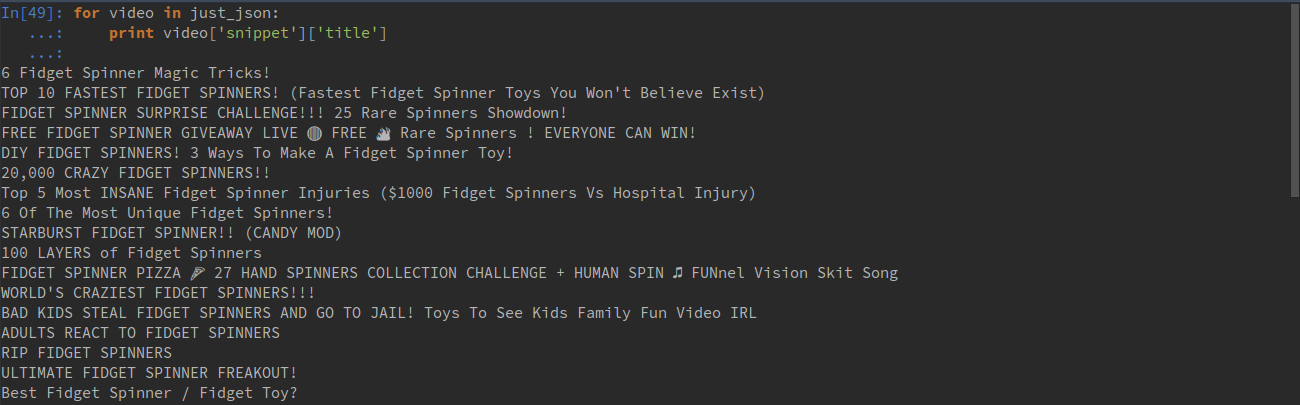
Fidget spinner pizza? Huh?
Ok, onward. Now, we figured out earlier that our output consisted of 50 distinct videos. That’s great and all — certainly way more videos about spinners than I’m interested in watching — but, that couldn’t be all of them, right?
Right. If we want more than 50 videos, which is the maximum we can get in one request, we have to ask for another round of 50. We can do this by using that weird six-character string we saw earlier … also known as a token.
If we send the token with the next request, YouTube will know where it left off, and send us the next 50 most-relevant results. Let’s try.
2
youtube_search("spinners", token=token)
Now we have:
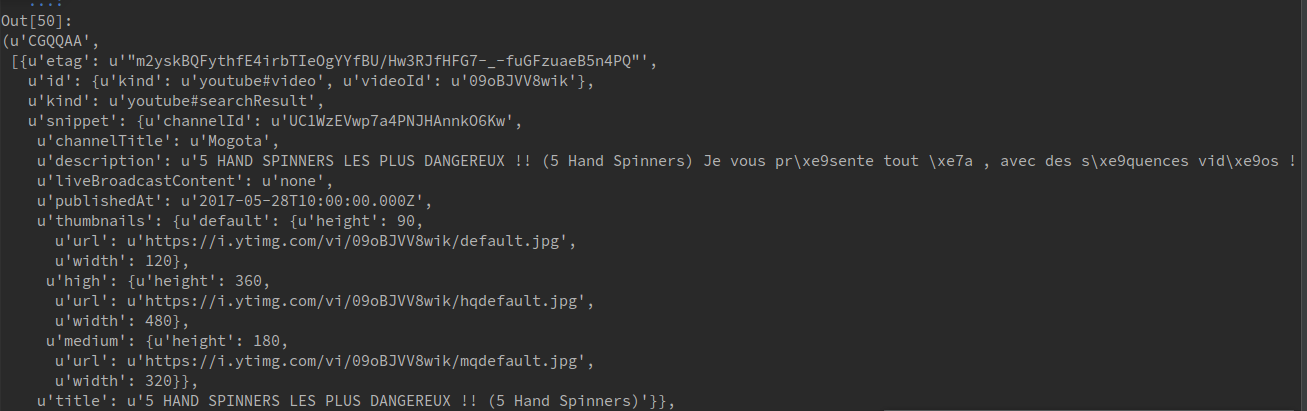
Awesome. Fifty more videos about spinners. Also, if you noticed, we got another token. If we want to keep going, we just rinse and repeat with that token.
Obviously doing it this way would really suck. Instead, we can write a function to automate the process a bit.
Automate the process
- Instantiate a dictionary to store results
Before we write our function, let’s instantiate a dictionary outside of it with the variable names we want to save.
2) Define our function
We can name our function grab_videos and add two parameters. The first is the keyword, while the second is an optional parameter for the token.
3) Add
1 | <strong class="markup--strong markup--p-strong">youtube_search</strong> |
and save our variables
Just like before, we’ll do a simple search with the
1 | youtube_search |
function and save our token and JSON results separately.
2
3
token = res[0]
videos = res[1]
4) Loop through results, append to dictionary & return token
print "added " + str(len(videos)) + " videos to a total of " + str(len(video_dict['youID']))
2
3
4
video_dict['youID'].append(vid['id']['videoId'])
video_dict['title'].append(vid['snippet']['title'])
video_dict['pub_date'].append(vid['snippet']['publishedAt'])
return token
I also added a little print statement here to update us on the number of videos we have collected each time the function is called.
Finally, we return the token so we can use it the next time we call the function.
5) Call function with while statement
Now that we’ve written the function, we can write a few short lines of code to put it to work.
First, we’ll call the function with our keyword, saving the results to the variable token.
We can then use a while statement to check if the function returned a valid token (i.e. there are more results) or if we’ve hoovered up everything. If it sees “last_page”, it will stop the execution of the code.
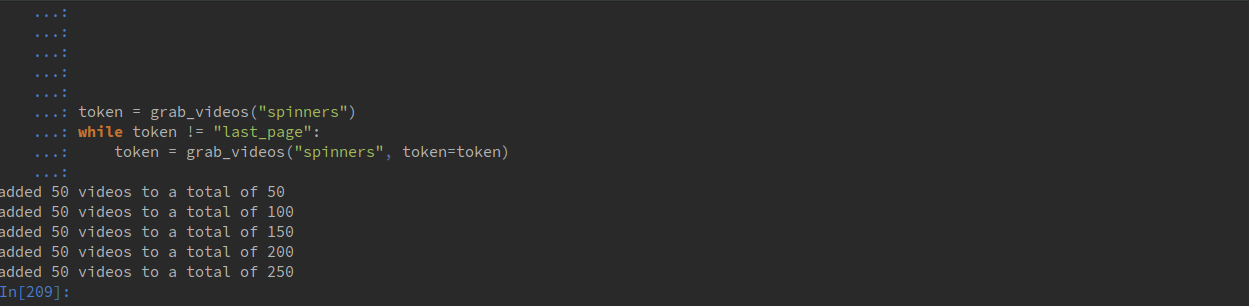
token = grab_videos("spinners")
while token != "last_page":
token = grab_videos("spinners", token=token)
Output should look like this:
Conclusion
Alright, now you’re at least in part ready to start doing your own data collection on YouTube.
If this article was helpful, please let me know via e-mail or in the comments section. If not, I’ll take up some other hobby! Stayed tuned for parts two and three.